
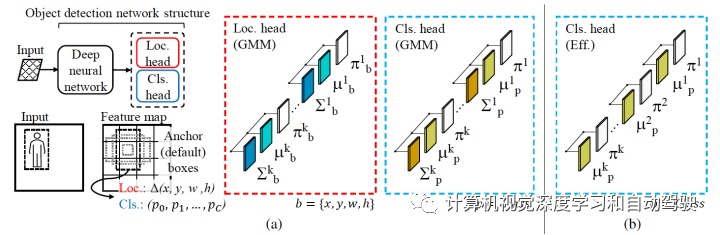
ntainer css-xi606m style=text-align: center;而下图是该目标检测框架的概览:与传统目标检测器的主要区别在于定位头和分类头(两个分支)。a)不具有确定性输出,而是为每个输出学习 K 分量 GMM 的参数:定位头的边框坐标和分类(置信度)头的类密度分布;b) 从 GMM 的分类头中消除方差参数,提高分类头效率。
ntainer css-xi606m style=text-align: center;
ntainer css-xi606m style=text-align: center;
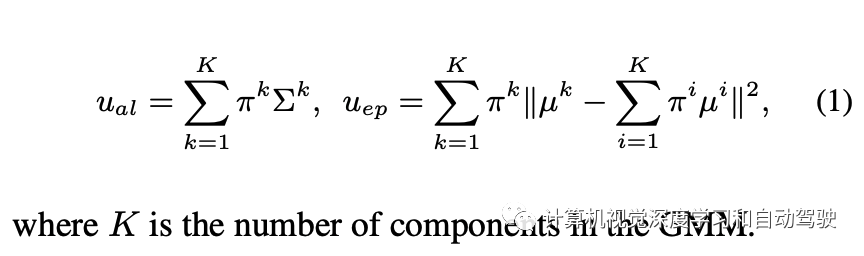
ntainer css-xi606m style=text-align: center;
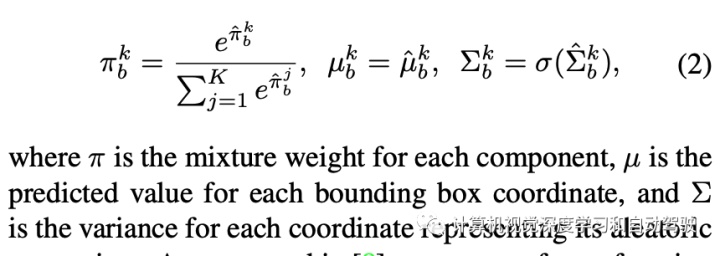
ntainer css-xi606m style=text-align: center;

ntainer css-xi606m style=text-align: center;
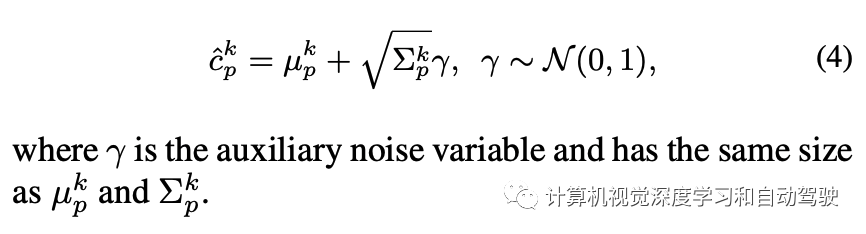
ntainer css-xi606m style=text-align: center;

ntainer css-xi606m style=text-align: center;
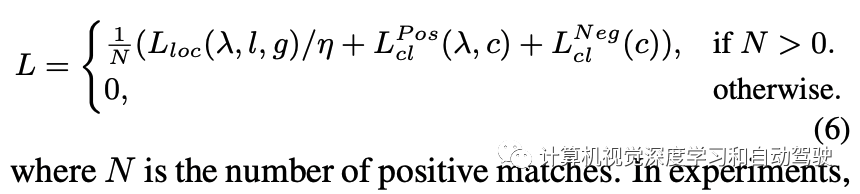
ntainer css-xi606m style=text-align: center;
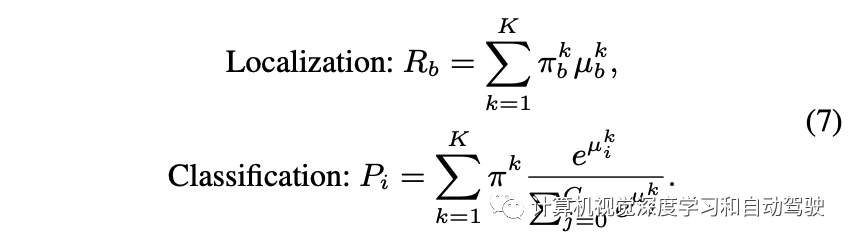
ntainer css-xi606m style=text-align: center;

ntainer css-xi606m style=text-align: center;
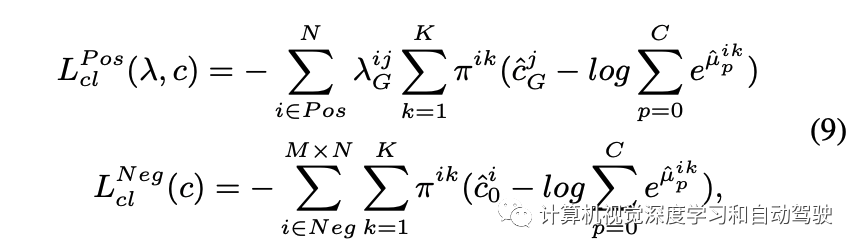
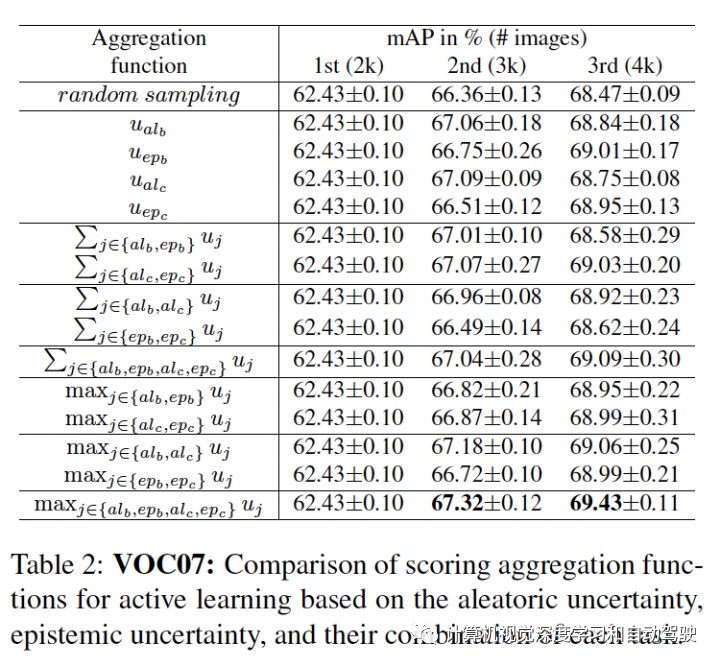
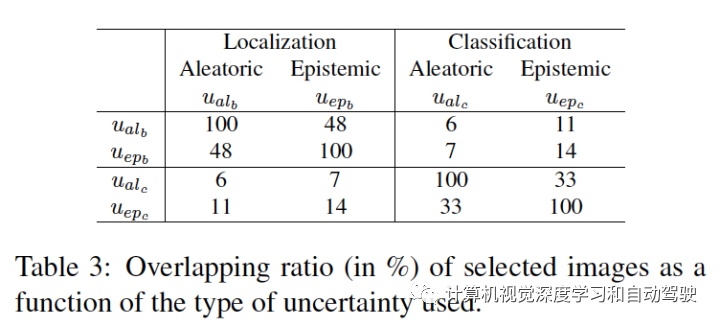
主动学习的评分函数为每个图像提供一个单值表明其信息量。评分函数通过聚合图像中每个检测目标的两种不确定性值来估计图像的信息量。具体来说,让 U = {uij } 是一组图像的不确定性集,其中 uij 是第 i 个图像第 j 个目标的不确定性。对于定位,uij 是 4 个边框输出的最大值。首先,z-score 归一化 (u ̃ij = (uij − μU )/σU ),补偿一个事实:边框的坐标值是无界的,并且图像的每个不确定性可能有不同的范围。然后,对每个图像分配检测目标的最大不确定性 ui = maxj u ̃ij。凭经验发现,在坐标和目标上取最大值比取平均值要好。用上述算法,每个图像获得四个不同的归一化不确定性值:用于分类和定位的两个不确定性,分别为 u = {uiepc , uialc , uiepb , uialb }。剩下的部分是将这些分数聚合成一个。聚合这些不确定性评分函数得到不同组合,包括求和或取最大值。正如在实验中展示的那样,取最大值会获得最高评分。
ntainer css-xi606m style=text-align: center;
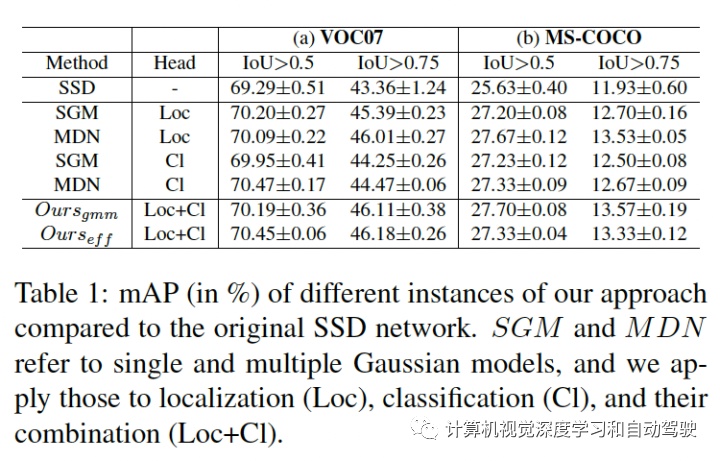
ntainer css-xi606m style=text-align: center;
ntainer css-xi606m style=text-align: center;
ntainer css-xi606m style=text-align: center;
ntainer css-xi606m style=text-align: center;
ntainer css-xi606m style=text-align: center;
ntainer css-xi606m style=text-align: center;
ntainer css-xi606m style=text-align: center;

汽车测试网-创办于2008年,报道汽车测试技术与产品、趋势、动态等 联系邮箱 marketing#auto-testing.net (把#改成@)
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏


